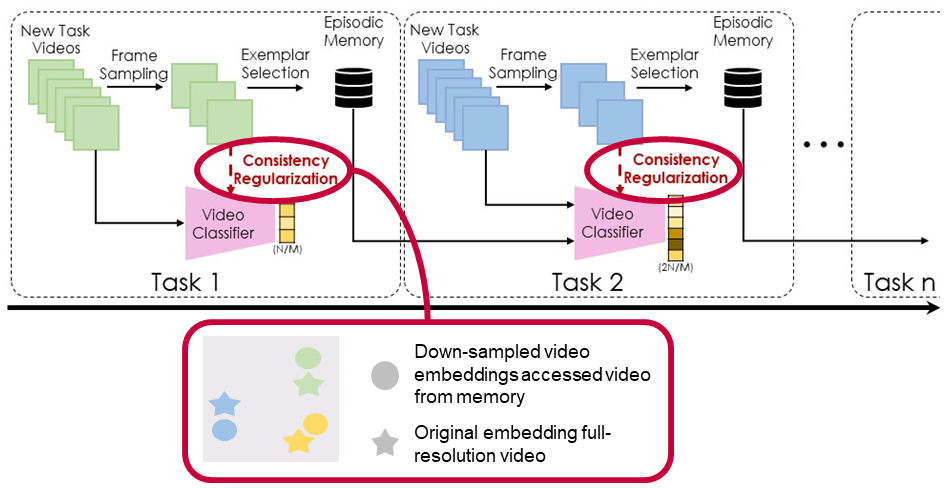
Temporal Consistency Regularization
We also present a novel strategy for rehearsal methods to reduce memory consumption while improving performance. It is a temporal consistency regularization loss, represented by the red dashed arrow in the figure. This loss constrains the network to estimate similar representations for the original clip and its temporally down-sampled version. Thus, it enables the network to remember from the temporally down-sampled videos of the previously learned tasks.
\[L_{c} = (1-\lambda)L_{cls}(F(X), Y) + \lambda L_{cls}(F(X^d), Y)\] Where \(L_{cls}\), is the cross-entropy loss. \(Y\) is the ground truth label of \(X\) and \(X^d\). \(X^d\) is the temporally down-sampled version of \(X\). \(\lambda\) is the consistency regularization factor.
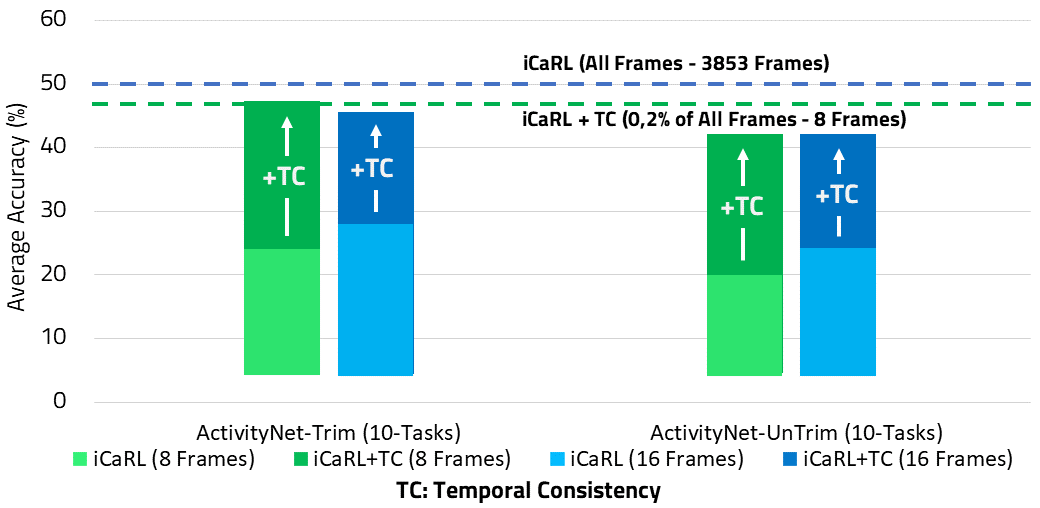
We achieve outstanding results with the temporal consistency loss, especially in the dataset that requires more sophisticated temporal reasoning like ActivityNet. On both versions of ActivityNet, Trim, and Untrimmed, our regularization loss enhances the performance by 24% when we save eight frames. Likewise, it remains close to the best performance with all frames shown in the red dashed line, but with 0.2% of the memory size.