 A Novel Video Class Incremental Learning Benchmark
A Novel Video Class Incremental Learning Benchmark
We introduce vCLIMB, a novel video continual learning benchmark. It is a standardized test-bed to analyze catastrophic forgetting of deep models in video continual learning to promote and facilitate research in this area. vCLIMB proposes eight different continual learning scenarios from three well-known video datasets: UCF101, Kinetics, and ActivityNet. For the first time, we create realistic and challenging scenarios using untrimmed videos taken from ActivityNet. Likewise, we encourage redefining the memory size of rehearsal methods in terms of stored frames.
Announcement: Stay connected! vCLIMB will be added to Avalanche soon.
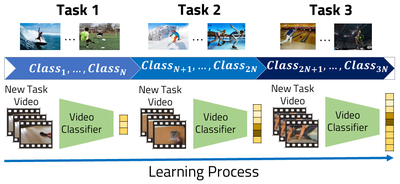
With 500 hours of video from diverse categories uploaded to YouTube every minute and a billion people actively using TikTok every month, real-world deep-learning pipelines rarely involve a single fine-tuning stage. Instead, these pipelines could require the sequential fine-tuning of large models in a set of independent tasks learned sequentially. Under these conditions, deep neural networks suffer from what is known as catastrophic forgetting, where the fine-tuning on novel tasks significantly reduces the performance of the model in a previously learned task. Continual learning (CL) directly models such a scenario by adapting a neural network model into a sequential series of tasks. We focus on the most challenging case of CL: class incremental learning (CIL), where the labels and data are mutually exclusive between tasks, training data is available only for the current task, and there are no tasks ids.
We directly address this problem and propose vCLIMB (video CLass IncreMental Learning Benchmark), a novel benchmark devised for evaluating continual learning in the video domain. Our test-bed defines a fixed task split on the original training and validation sets of three well-known video datasets: UCF101, ActivityNet, and Kinetics. vCLIMB follows the standard class incremental continual learning scenario but includes some modifications to better fit the nature of video data in human action recognition tasks. First, to achieve fair comparisons between video CIL methods that use memory, we re-define memory size to be the total number of frames instead of the total number of video instances the memory can store. This means we are not only concerned about selecting the best videos to store in memory, but we also want to identify the best set of frames to keep in memory. Second, since fine-grained temporal video annotations are expensive (especially for long videos), we analyze the effect of using trimmed and untrimmed video data in continual learning. To the best of our knowledge, this is the first work to explore continual learning with untrimmed videos. Third, We present a novel strategy based on consistency regularization that can be built on top of memory-based methods to reduce memory consumption while improving performance.